ISSN : 2349-3917
American Journal of Computer Science and Information Technology
Abstract
An Efficient Classification Model for Unstructured Text Document
Document classification has become an important field of research due to the increase of unstructured text documents available in digital form. It is considered one of the key techniques used for organizing the digital data by automatically assigning a set of documents into predefined categories based on their content. Document classification is a process that consists of a set of phases, each phase can be accomplished using various techniques. Selecting the proper technique that should be used in each phase affects the efficiency of the text classification performance. The aim of this paper is to present a classification model that supports both the generality and the efficiency. It supports the generality through following the logical sequence of the process of classifying the unstructured text documents step by step; and supports the efficiency through proposing a compatible combination of the embedded techniques for achieving better performance. The experimental results over 20-Newgroups dataset have been validated using statistical measures of precision, recall, and f-score. The results have proven the capability of the proposed model to significantly improve the performance.
Author(s): Mowafy M, Rezk A and El-bakry HM
Abstract | Full-Text | PDF
Share This Article
Google Scholar citation report
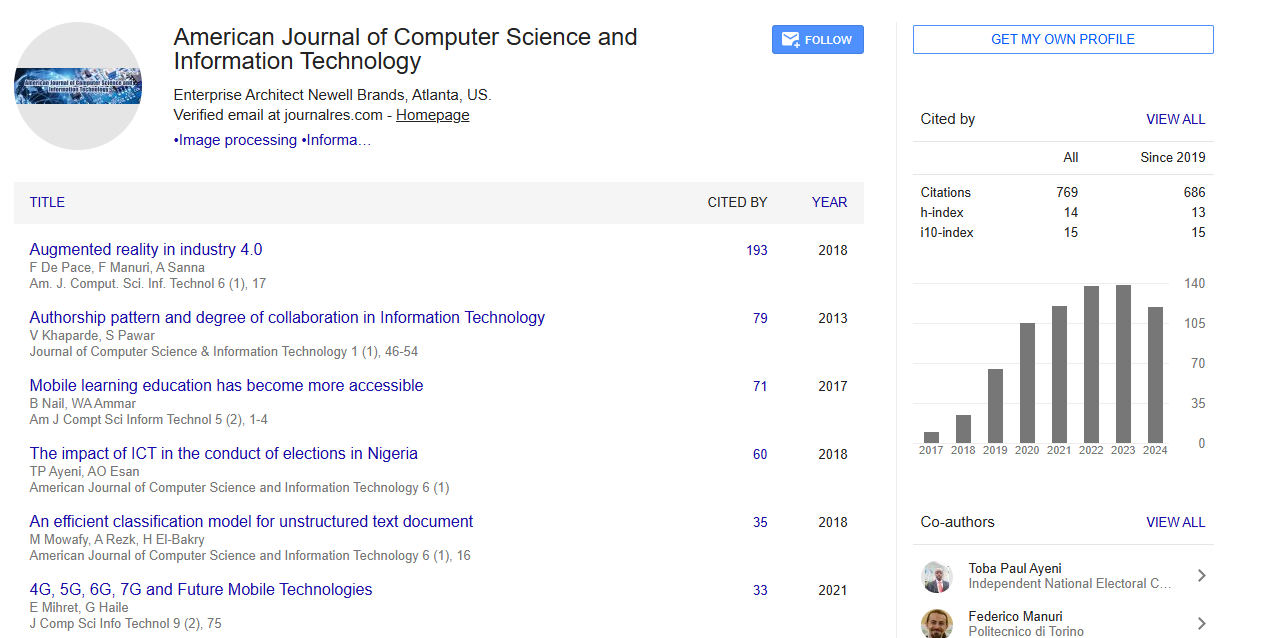
Citations : 769
Abstracted/Indexed in
- Google Scholar
- Genamics JournalSeek
- China National Knowledge Infrastructure (CNKI)
- CiteFactor
- Open Academic Journals Index (OAJI)
- Directory of Research Journal Indexing (DRJI)
- Jour Informatics
- CiteSeerx
- Journal Index.net
- Secret Search Engine Labs
Open Access Journals
- Aquaculture & Veterinary Science
- Chemistry & Chemical Sciences
- Clinical Sciences
- Engineering
- General Science
- Genetics & Molecular Biology
- Health Care & Nursing
- Immunology & Microbiology
- Materials Science
- Mathematics & Physics
- Medical Sciences
- Neurology & Psychiatry
- Oncology & Cancer Science
- Pharmaceutical Sciences